AI beats Chrome Dino Game:
Made By:

Unlike a lot of other people's approaches where the dino game was rebuilt from scratch or source code adjusted to make it work with their AI, this game developed by Saral Tayal is as true to the real game as possible.
It works by actually capturing screenshots of the real game and learning from that. Furthermore, the coolest part of this AI is that it's only around 200 lines of code!
This AI uses reinforcement learning which as the name suggests is a form of AI learning where the AI learns from rewards given by the game.
This project has a very simple reward function:
If the AI dies it gets a negative tender board and if it lives it gets a +1 reward.
This AI was designed using Q learning. Q learning is a model-free reinforcement learning algorithm to learn a policy telling an agent what action to take under what circumstances.
Here the AI actually learns to estimate their expected reward of doing each action so in this case we have three actions:
- Jump
- Duck, or
- Do nothing
If the AI in a situation decides to jump it might learn that the expected reward is +1 while the expected reward of going straight or the no action would be -10.
Traditionally Q learning was done in a tabular manner where each state and action meant a position in the game and potential action is mapped to the expected Q value in a tabular table like sense and this tabular learning happens with this learning algorithm.
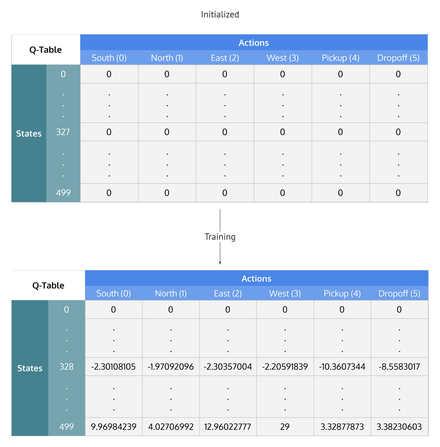
However this method of tabular learning does not really carry you well to a chrome dinosaur game because we're dealing with images here and each image has billions of potential values and therefore our Q learning table would be too long.
So instead of that, Saral actually borrowed techniques for machine learning such as neural nets and deep learning to create the AI that estimates the expected value for each position.
This is done using convolutional neural net or CNN.
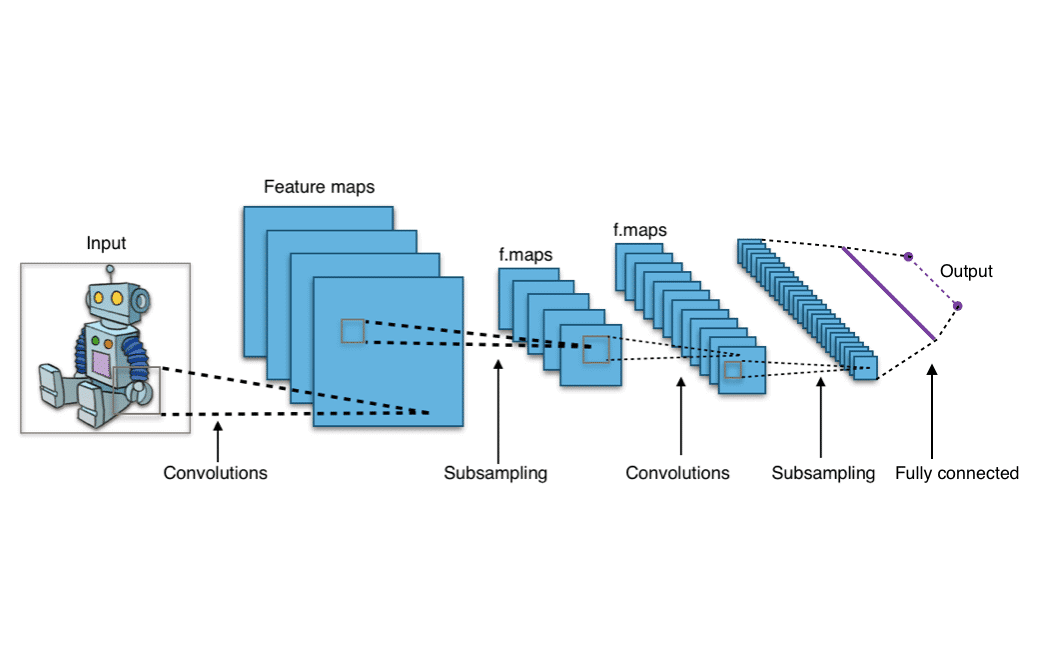
As the name suggests, function approximation is just an approximation of the various Q values so therefore it's not technically as accurate as doing the tabular sense but in the case of chrome dino game it's the most practical way for the Chrome AI to actually learn.

The AI has been divided in three broad categories:
- The agent
- The environment, and
- The learning loop
How it works:
The agent is the actual AI that controls the dinosaur and is responsible for choosing what actions to take and also learning from those actions based on the reward it gets. The agent is fed its inputs or its images from the environment.
The environment will actually stack four consecutive frames or images together to allow the agent to learn the speed of the game. Since the game does speed up as it progresses the environment is also responsible for providing the agent a reward signal and letting the agent know when the game is over.
Traditionally an environment used to be the game itself but in this case since we're using the chrome AI game that's already built in, our environment simply needs to control that.
So in this case the environment is actually responsible for taking the screenshots, packaging them up into layers of four images and also determining the rates of pixel values when the game has ended and appropriately giving a reward signal based on that.
Also, the image resolution was reduced, converted to black & white and also added a bit more contrast to make it easier for the agent to learn on.
Lastly we have the actual learning loop. This is where the magic happens. This is where the AI actually plays the game and learns from its experiences.
The loop is fairly straightforward and no matter what reinforcement learning architecture you use this loop is going to stay pretty much the same. The loop starts by resetting the environment. From here on, the agent picks an action to take, the environment executes the action and returns the appropriate reward whether the game is done and also the next state that the AI has ended up in.
The AI will actually remember the reward in the next state based on the original state action pair using something called the experience replay.
You can think of the experience replay like the memory of the AI now once the game is finished the AI can actually go back this experience replay, randomly select a couple of experiences and learn based on those experiences.
Demo:
This video shows how the neural network learns with the reward system and beats the chrome dino game.
Want to train your ML Models at 5X lower cost?
If yes, then sign up: 🙌
Get access
Code:
Want to try out this code? Implement it right away using this:
GitHub repo for Chrome Dino AI Game
Get your AI project featured
Fill out this Google Form and get a chance to be featured in this growing AI community