
There is no doubt that Artificial Intelligence (AI) is becoming more powerful by the day, and that it has the potential to do some really amazing things to make our work easier than ever before.
Talking about computer vision, a field of AI where you can detect and manipulate visual content using algorithms, we have seen several computer vision models and approaches getting released to tackle object detection and removal from images and videos. But there were always artifacts left behind thus giving an impression it was manipulated using software. Now, what if we tell you that recently a research paper was published that not only suggests a way to deal with objects in the content but also with their reflections, shadows, and other visual impacts in the scene.
We will walk you through how AI researchers performed a great job at building this algorithm and how you can implement it in your project too.
These computer vision approaches deal with a great amount of Image segmentation use.
What is Image Segmentation?
One of the most important Computer Vision procedures is segmentation. Picture segmentation allows you to group portions of an image that belong to the same object category. This technique is sometimes referred to as pixel-level categorization (or pixel-level classification). It may also be used to images and videos.
 Source
Source
In the image above, a computer vision algorithm has been used to apply masks on all the cars and predestrians recognized in the scene. But as you can clearly see, the shadows of different cars have not been masked.
The reason is that the algorithm failed to recognize the impact caused by the object to its surroundings in that scene.
Now, what if you wanted to get rid of the car and its shadow seen in the left side of the road? Image segmentation and other algorithms may assist us in removing an object, but their shadows may be difficult to remove. Especially when dealing with movies, where the lighting dynamics and interactions of an item with its surrounding environment changes on a regular basis.
Thus, to eliminate visual effects like reflections, shadows, etc, a simple image segmentation approach may not work. It should be obvious by now that traditional models have limitations when it comes to the work we described previously in this article.
Researchers have developed a new method called Omnimatte to overcome these limitations.
Omnimatte: Associating Objects and Their Effects in Video
By: Erika Lu, Forrester Cole, Tali Dekel, Andrew Zisserman, William T. Freeman, Michael Rubinstein, Google Research, University of Oxford, Weizmann Institute of Science
Official website Implementation Code
When it comes to segmenting objects in pictures and videos, computer vision is becoming more and more successful. However, scene effects connected to the items—such as shadows, reflections, and smoke—are often missed.
Such scene effects must be identified in order to not only improve our fundamental knowledge of visual scenes but also help us with a number of applications, such as automatic removal, duplication, or enhancement of objects in videos.
In this approach, objects are automatically associated with their effects in videos, which is a step in the right direction towards addressing the problem.
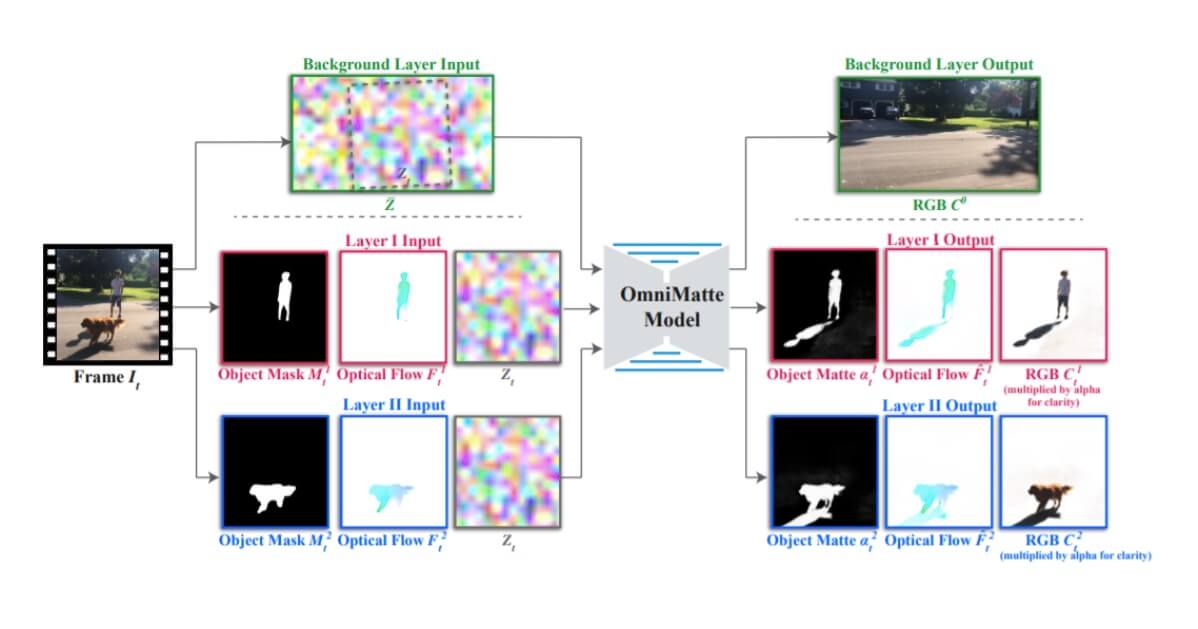
1. Each subject is estimated by using an ordinary video and a simple segmentation mask of one or more items.
2. The omnimatte for each subject consists of an alpha matte and color image that comprises the subject and all of its important time-varying.
3. In order to train the model, which is entirely unlabeled and automatically produces omnimattes for any objects and effects, we just utilize the input video.
 Source
Source
What is Omnimatte?
For each of the objects of interest in an ordinary video, we estimate an omnimatte - an alpha matte and color picture that includes the object and all other associated effects with it over time. Now, let's dig further by looking at a few examples.

In the above image,
- “Original” refers to the input given to the algorithm.
- On detection of the desired object in the scene, a mask is added to it. This is referred to as the “Input mask” in the above image.
- Now, here is the interesting part: “Omniatte (alpha)”. On top of the “input mask”, another masking has been added for the detected visual impact generated by the object like reflections, shadows, etc.
- “Omnimatte (RGBA)” then corresponds to the object and visual impacts around it segmented from the scene in RGB(colours).
- And finally, the algorithm will completely remove the objects as you can clearly see in the last part.
There are a lot of applications where Omnimatte can play a great role in making the job of a video editor much easier and unleash a new kind of content creation capability for the entire community.
Omnimatte Use Cases
As seen in the image below, Omnimatte has been used to automatically add mask on the horse, horse rider and their associated shadows and them completely remove them from the scene.
 Source
Source
Due to the fact that this approach is so reliable in complete segmentation of objects and humans from visual media, it opens the door for new magical effects.
- Removing Shadows, reflection and ripples in water.
- Dust particles (continuously changing their position over time).
- Smoke from a drifting car.
- It can also make the color pop.
- It can even change the background in the video.
 Source
Source
Limitations of this approach
While this approach allows for modest changes from a static background via smooth, coarse geometric, and photometric offsets; omnimattes must be adjusted by adding background components when it does not adequately mirror the background (e.g., rocks and grass).
It cannot, however, detect objects or effects that remain fully fixed relative to the background throughout the movie. These issues might be overcome by providing a backdrop representation that clearly depicts the scene's 3D structure.
Implementation Code
So, what do you think about this research and new algorithms? What would you use this technique for?
You can get started with the code implementation here.